LLMs - 101
- Gabriel Pinto
- Llm
- 21 de maio de 2024
- 8 min
- Medium Link
Índice
Neste artigo vamos discutir LLMs, o que são, onde vivem? Nessa sexta, na bna.dev.
O objetivo aqui é mostrar como funcionam e como você pode escolher a ideal para as suas necessidades.
AI ou LLM? Entendendo as diferenças
Simplificando bastante:
- AI = conceito amplo. Existe há algumas decadas e está no nosso cotidiano já faz um tempinho, por exemplo: Alexa / Siri, Instagram te recomendando coisas que você acabou de falar com alguém, Google Translator, robôs PICAS da Boston Dynamics desde os anos 90 e, para finalizar, técnicas de predição de câncer por fotos em 2015 - sim, 2015 foram 9 anos atrás, eu nem era calvo .
- LLM = uma pequenina porção de AI. É o uso de um dos tipos de AI para completar uma única função: prever palavras baseadas um contexto dado 😄.
Modelos text-to-speech ou image generation não são LLMs. Só mais alguns dos pedaços de AI.
Se você tem interesse nesses outros tipos de modelos, me avise!
Como LLMs funcionam?
Antes que explicar, só uma curiosidade:
E se eu te disser que toda a fundação matemática e estatística de LLMs existe por décadas?
Sim, é verdade. LLMs são baseados em cadeias de Markov, inferência Bayesiana e redes neurais. Todas existem há anos. O que realmente mudou recentemente foram as GPUs e TPUs. Elas que possibilitaram a habilidade de treinar um LLMs com dataset ENORMES e, igualmente importante, de computar as suas respostas em real-time basicamente!
Claro, elas também facilitaram um monte de operações e desenvolvimentos matemáticos mais complexos!
Mas agora, vamos lá, LLM 101:
- datasets IMENSOS (to de olho em você Reddit vendendo a gente por aí);
- Cálculos: Como um computador vai quebrar os textos do dataset - tokens, como esses tokens serão transformados em vetores e matrizes cheios de números e como a probabilidade de token x dado um contexto y será calculada;
- Treinamento do modelo: Agora você tem todas as probabilidades de token x dado um contexto y;
Agora é onde você entra no processo!
- Seu input: Você abre o chatGPT e faz uma pergunta;
- Tokenização: Todos os cálculos vão começar. No primeiro, a Open(não tão open assim)AI vai quebrar sua questão em tokens;
- Embedding (não vou tentar traduzir kk): Transformar esses tokens nas matrizes e vetores. A sua pergunta vai virar isso aqui:
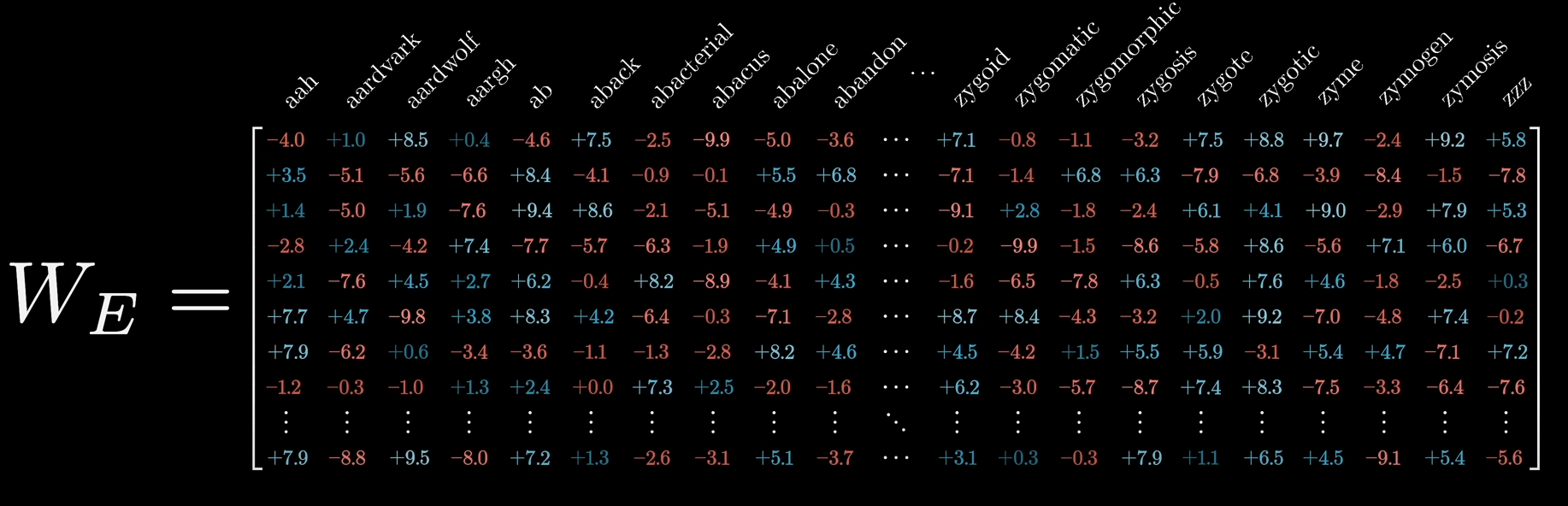 um vídeo bem daora sobre como LLMs funcionam
um vídeo bem daora sobre como LLMs funcionam - Inferência: Cálculo da probabilidade de token x dado um contexto y. Basicamente a sua matriz “embeddada” vai ser multiplicada por uma outra matriz terrivelmente grande que representa o modelo treinado e assim, você os n tokens que são mais próximos as suas perguntas;
- Refazer o processo para n tokens até ter toda a sua resposta;
- Unembedding: Transformar os tokens em palavras até porque eu gostaria de acreditar que ninguém aqui divergiu e agora tá lendo vetores na rua por aí.
O que procurar em um LMM?
Parabéns, agora você sabe (maomenos) como um LLM funciona!
No entanto, tu simplesmente tá cagando e andando pra isso. Só quer usar o coiso e AI e acabou, pô. Completamente justo.
Tudo que eu vou te explicar aqui para frente vai te ajudar bastante, porque vou focar em como você maximiza quais LLMs usar no seu dia-a-dia.
Eu realmente acredito que duas coisas acontecem com muitas pessoas:
- Tá achando LLM meio caro dependendo do seu uso;
ou
- Poderia usar LLMs mais indicadas para o seu use-case.
Características de um LLM
Vamos começar diferenciando as diferentes características que LLMs têm.
Um bom conselho é o artificialanalysis.ai . A grande maioria de LLM e seus provedores são colocados em comparação nesse site e fica MUITO fácil ver as diferenças.
Qualidade
Significa o quão bem o LLM te responde. Atualmente há vários métodos para pontuar LLMs nesse aspecto e cada um ta dará uma perspectiva diferente em quão boa a resposta é.
Exemplos:
- MMLU -> avalia a performance de models multi-linguísticos. Quer dizer: o quão bem ele responde diferentes tipo de conhecimento. Detalhe: é medido somente perguntas e respostas; e é aquele que colocam o LLM para fazer ENEM e ver o quão bem ele vai.
- MT-bench -> ao invés de perguntas e respostas, é baseado em turnos (cadeia de perguntas e respostas). Desta forma, o quão bem LLM segue instruções é medido.
- HumanEval -> esse já é muito mais focado em como a LLM gera códigos!
… e tem muitos outros métodos.
Um exercício rápido:
A partir do artificialanalysis.ai, conseguimos ver que Claude 3 Opus, Gemini 1.5 Pro e LLama 3 (70B) conseguem entregar uma qualidade parecida com o GPT-4 Turbo - provalvelmente vai sair um artigo só para o GPT-4o.
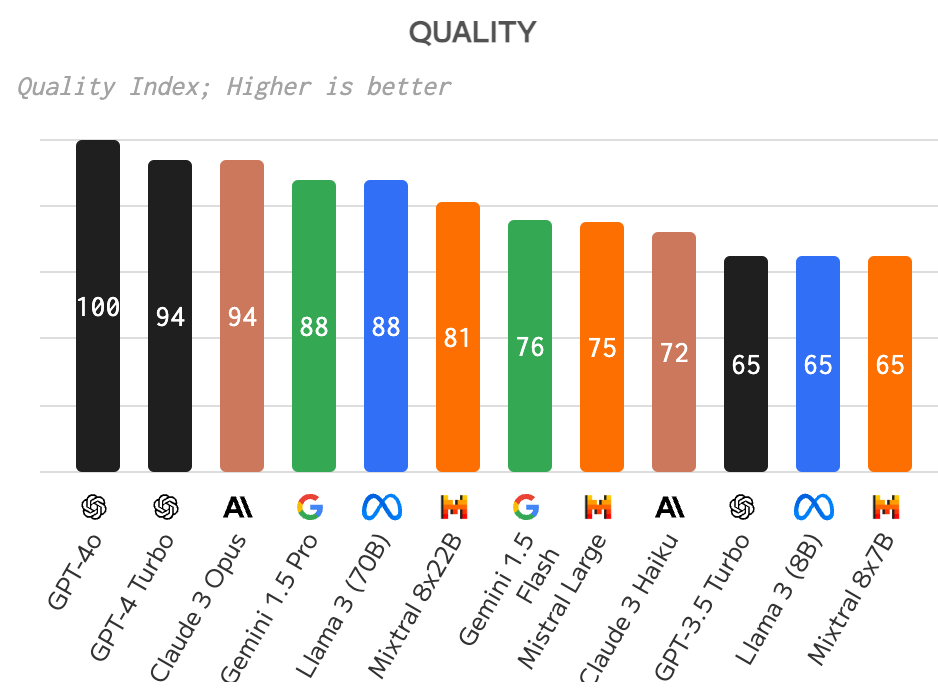 comparação da qualidade de LLMs
comparação da qualidade de LLMs
Mas ao mesmo tempo, você consegue ver que a note no MMLU é praticamente um empate.
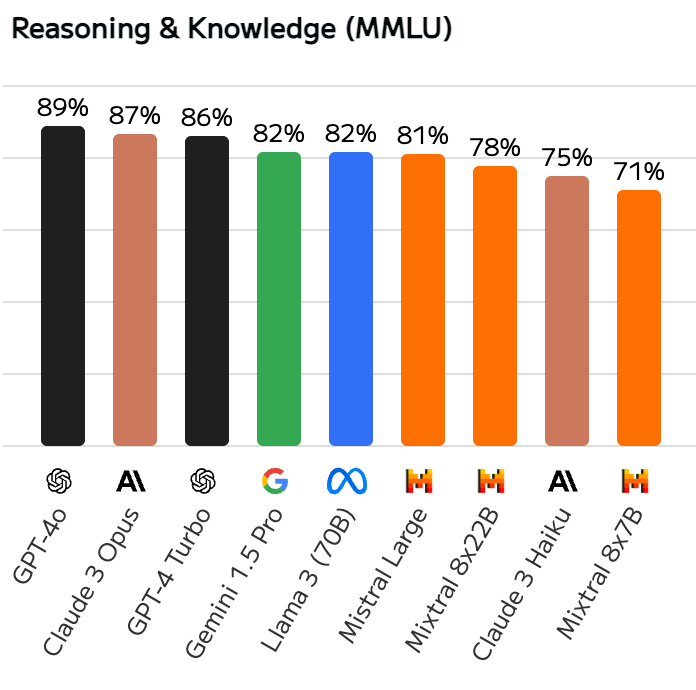 main LLMs MMLU score comparison
main LLMs MMLU score comparison
Ou seja: se você só está usando LLM para tasks mais genéricas (sem muito código ou instruções), você provavelmente nem sentiria diferença usando todos esses modelos.
Velocidade
Entenda velocidade como: quantos tokens/palavras o LLM consegue mandar por segundo.
Era mais legal debater velocidade duas semanas atrás quando o GPT-4o não existia. Mas velocidade ainda é um componente chave para escolher um LLM.
Quantas vezes você já esteve tipo: “mano, chatGPT só me responde, por favor!” E aí você caiu em atualizar a “tab” só para ver que você perdeu tudo e vai ter refazer o prompt inteiro.
Mas também é super importante para grandes infraestruturas que dependem de LLMs para atender clientes. É claro que você preferirá um modelo com uma capacidade de resposta mais rápida.
Um exercício legal é esta comparação aqui:
- O quão INSANAMENTE mais rápido o GPT-4o é comparado aos modelos mais precisos;
- O quanto mais INSANAMENTE mais rápidos são os modelos menores como 1.5 Flash e Llama 3 (8B).
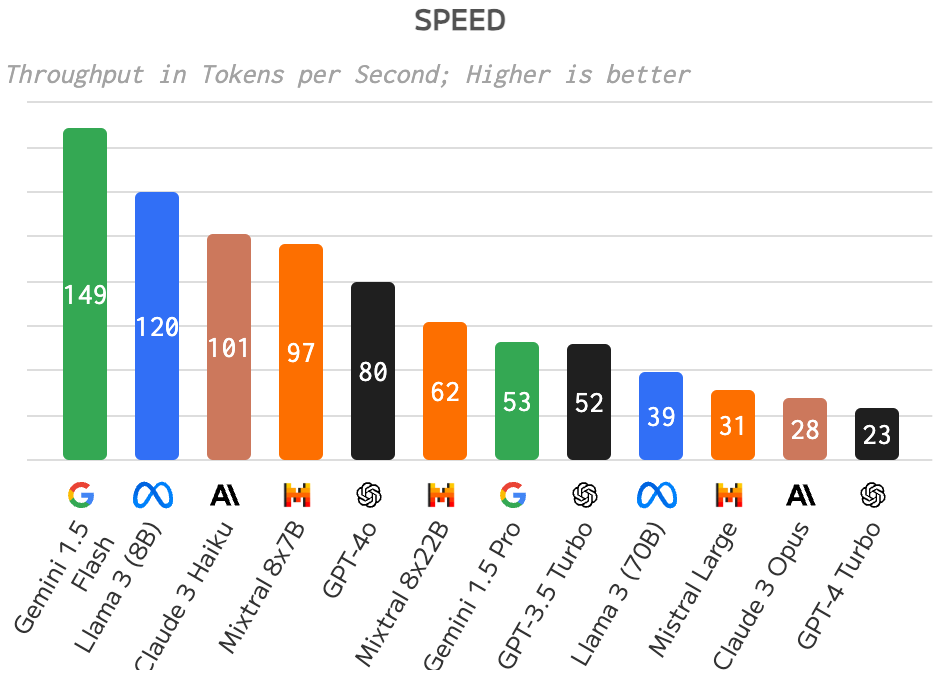 comparação de velocidade entre LLMs
comparação de velocidade entre LLMs
Então aqui de novo temos uma oportunidade legal de usar modelos menores que são muito mais rápidos para use-cases mais simples se é o seu caso.
Código aberto ou fechado.
Antes de uma tabela de pros e contras. Só um rápido contexto.
Modelos de código fechado -> alguém criou um modelo e está guardando só para eles como o modelo funciona. Exemplos: GPT4 da ClosedAI e modelos da Anthropic. Modelos de código aberto -> alguém criou um modelo e deixou disponível na internet para ver ou mudar como funciona. Exemplos: modelos Llama da Meta (Zuck ❤️) e alguns modelos da Mistral (🇫🇷 ❤️ - o chatGPT da Mistral é literalmente LeChat).
Tabela prometida:
| Áreas | Pros e contras |
|---|---|
| Custo | Você pode deployar modelos abertos na sua própria infraestrutura. Caso você saiba configurar e manter bem a sua infra, pode fazer sentido. Ao mesmo tempo, tem muitos provedores que estão competitindo hoje para te prover com modelos abertos em um preço amigável. |
| Velocidade | Esse aqui é mais complicado e acho que ficará mais claro quando eu entrar nos provedores de API. Mas eu digo que a competição tem sido benéfica e principalmente com o Llama 3 creio que modelos abertos hoje têm uma pequena vantagem, mesmo com o GPT-4o. |
| Inovação | Existe uma comunidade inteira (pesquise sobre hugging face) que estão fazendo muuuitas coisas. Existe uma boa oprtunidade de você conseguir encontrar um modelo treinado por alguém que funcionará perfeitamente para o seu use case. Você pode encontrar também modelos sem censura 😆 use-os a seu próprio critério. |
| Suporte | Aqui o bom e velho capitalismo funciona bem. Você paga modelos fechados, você terá um bom suporte! |
| Customização | Você pode treinar modelos abertos da maneira que quiser. Os fechados são mais limitados nesse aspecto. |
| Segurança | Aqui temos dois lados: um é a ter a confiança que o LLM não vai responder coisas que não deveria - aqui modelos fechados ganham; outro é que o que os seus usuários respondem estão seguramente guardados - aqui funciona igual aos custos, se você tem uma ótima segurança de dados modelos abertos funcionarão melhor, já que voc6e terá controle sobre tudo. |
| Bem-estar social | Precisamos de modelos abertos! |
Sim, provalmente sou enviesado.
Features de Provedores de LLMs
Em minha singela opnião, está é seção mais importante de todo o artigo. De longe.
A maioria de nós, eu de alguns meses atrás incluso, não percebemos que OpenAI, Mistral, Anthropic, Google, Meta e outros são desenvolvedores de LLM. Somente uma parte de suas responsabilidades é criar uma UI e API para nós usarmos.
Com modelos abertos, existem uma possibilidade de haver distintas empresas focadas somente em como deployar LLMs da maneira mais eficiente possível para que nós possamos ter os preços mais baratos e as velocidades mais rápidas.
O exemplo mais legal é o groq. É uma startup de hardware que estão desenvolvendo um design específico de computação chamado LPU (Language Processing Unit™) para rodar LLMs. Desta maneira, eles conseguem ultrapassar a velocidade de todos os outros competidores por 2x no mínimo e, em tese, em preços mais camaradas.
Entrem em groq e testem. Você vai rodar um chatGPT que roda INSTANTANEAMENTE. Se quiser também, você consegue entrar no groqCloud, usar a API deles de graça e com rate limits bem honestos. Provavelmente tão burning cash agora.
Features de uma UI
Se você não é desenvolvedor e usa LLM somente para uso pessoal, essa é a seção importante e talvez as de preço e velocidade.
Aqui pessoalmente eu acho que a OpenAI não tem competidores. Especialmente com o GPT-4o, agora simplesmente não tem ninguém no mercado que consegue disponibilizar as mesmas features do chatGPT / playground.
É um só chat e ele pode além de gerar textos: gerar/ler imagens, ler documentos, ler sites, rodar códigos, tem a GPT store e agora ele também conversa com você no celular. É insano.
A Meta não tem nenhum playground para o Llama, o Gemini da Google.. bom, é o Gemini da Google. Você já usou o Gemini? Ah, foi o que eu pensei! E todos os outros provedores.. nenhum chega aos pés do chatGPT.
Que fique claro: não em como o LLM te responde, mas sim em features que a UI te proporciona. É por isso que eu digo, se você tá usando só para gerar textos, texta o groq. No mínimo, você vai abrir o site, fazer uma pergunta, ficar: “Eita rapaz! Que rápido” e nunca mais usar.
Eu pessoalmente uso groq para 95% das minhas tarefas e chatGPT para quando o bagulho fica treta. Quando por exemplo eu preciso que leia algum documento rápido ou gere alguma imagem. Mas em breve, espero que eu consiga aumentar isso para 100% quando eu terminar o gaboGPT ou bna.devGPT (vai ter um artigo sobre isso).
Features de uma API
Agora é papo de dev ou pelo menos para quem trabalha ou depende de devs.
Aqui eu acho que a OpenAI já não tem tanta vantagem. Para desenvolvedores, usar a API x ou y é, simplificando muito, só algumas linhas e uma API key.
Alguns pontos de atenção é se você precisa fazer um RAG (retrieval augmented generation - que é quando o chatGPT lê seus documentos) ou fine-tuning - nem vou entrar em re-treinar um modelo, fica para outra hora.
Vão ter alguns provedores que deixar RAG e fine-tuning mais simples, com uma UI ao invés de só conseguir pela API ou CLI (para leigos, lê-se: fazer coisas no terminal do seu PC). Especialmente o RAG pode ser uma dor cabeça, porque é algo muito mais frequente, o fine-tuning normalmente você só o faz uma vez.
Mas mesmo com esse problema, já tem tantas empresas como a ragapi.com ou bibliotecas como langchan e llama index que facilitam RAG e outras operações que deixar isso bem mais simples. Vai ter um outro artigo somente sobre como construir RAG e fazer fine-tuning do zero.
E assim, o problema para devs vira um pouco do mesmo: só algums linhas de código. Em alguns provedores um pouco menos, em outros, um pouco mais.
Price
Agravando ainda mais o case da OpenAI não ter tanta vantagem para API tem um ponto que eu ainda não discuti aqui: PREÇO.
Só quis discutir nesta seção, porque você só vai olhar com muito cuidado isso se você está vendendo algo que usa LLM. Se você só usa o chatGPT, você não ter tanta preocupação.
Aggravating even more the OpenAI case on not having the edge for API services there’s one point I haven’t discussed here: PRICE.
A partir da comparação de qualidade e velocidade que fizemos antes + a competição quem é que o melhor provedor de LLM, os preços para modelos abertos são BEM menores. A desvantagem de modelos fechados é que não há competição uma vez que eles são os únicos provedores de seus próprios modelos.
Usando o artificialanalysis.ai, vou mostrar um exemplo da diferença de preços entre modelos com qualidades similares com diferente provedores.
Exemplo: Llama 8 (70B) e vai ficar claro também, a importância desse modelo para o mercado.
Lembrete: Llama 8 (70B) teve pontuação de qualidade 88, GPT4 teve 94, Claude 3 Opus teve 74 too e Gemini, 88.
Em preço, Llama é 33x mais barato que Claude e 16x mais barato que GPT-4. Só para colocar em perpectiva, o preço para se revisar esse mesmo artigo em cada modelo seria:
Claude: USD 0,12
GPT-4: USD 0,06
Llama-3: USD 0,004
Esse é o preço médio. Se você usar groq ou deepinfra com Llama 3, o valor cai de USD 0,9 / 1M tokens para USD 0,6 (50x mais barato que Claude).
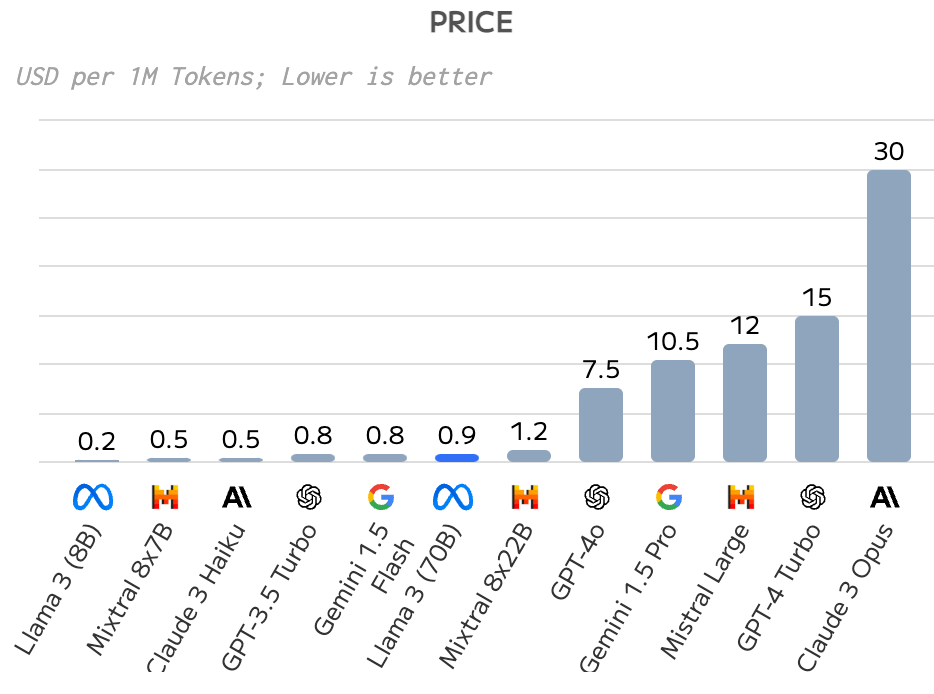 comparação de preços
comparação de preços
Velocidade
Ainda não acabamos, mas citando groq novamente.
Comparando todos os provedores de Llama 3 (70B), é 2x mais rápido que o segundo provedor e 15x que o último (claro que a Microsoft não vai rodar um modelo da Meta muito rápido).
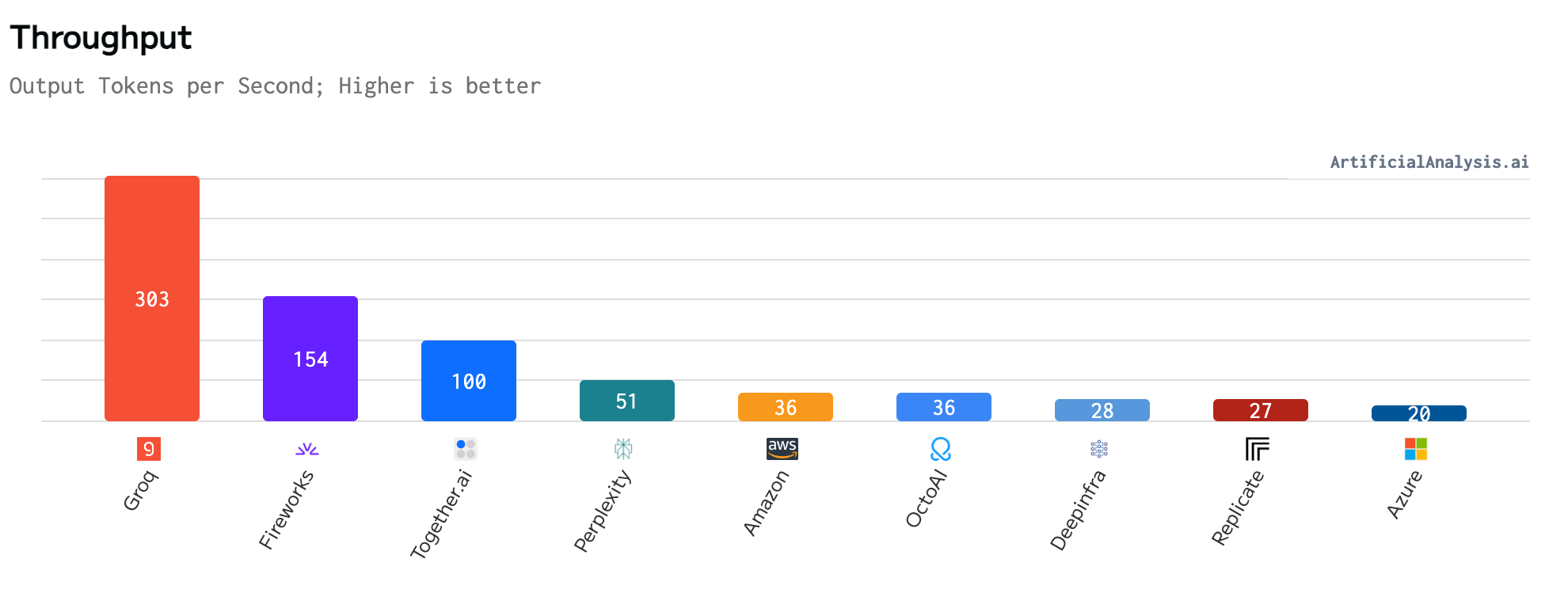 comparação de velocidade entre provedores de Llama 3
comparação de velocidade entre provedores de Llama 3
Até comparando com o GPT4o que é vendido como o mais rápido e que só tem a OpenAI como provedor. 3x mais rápido!
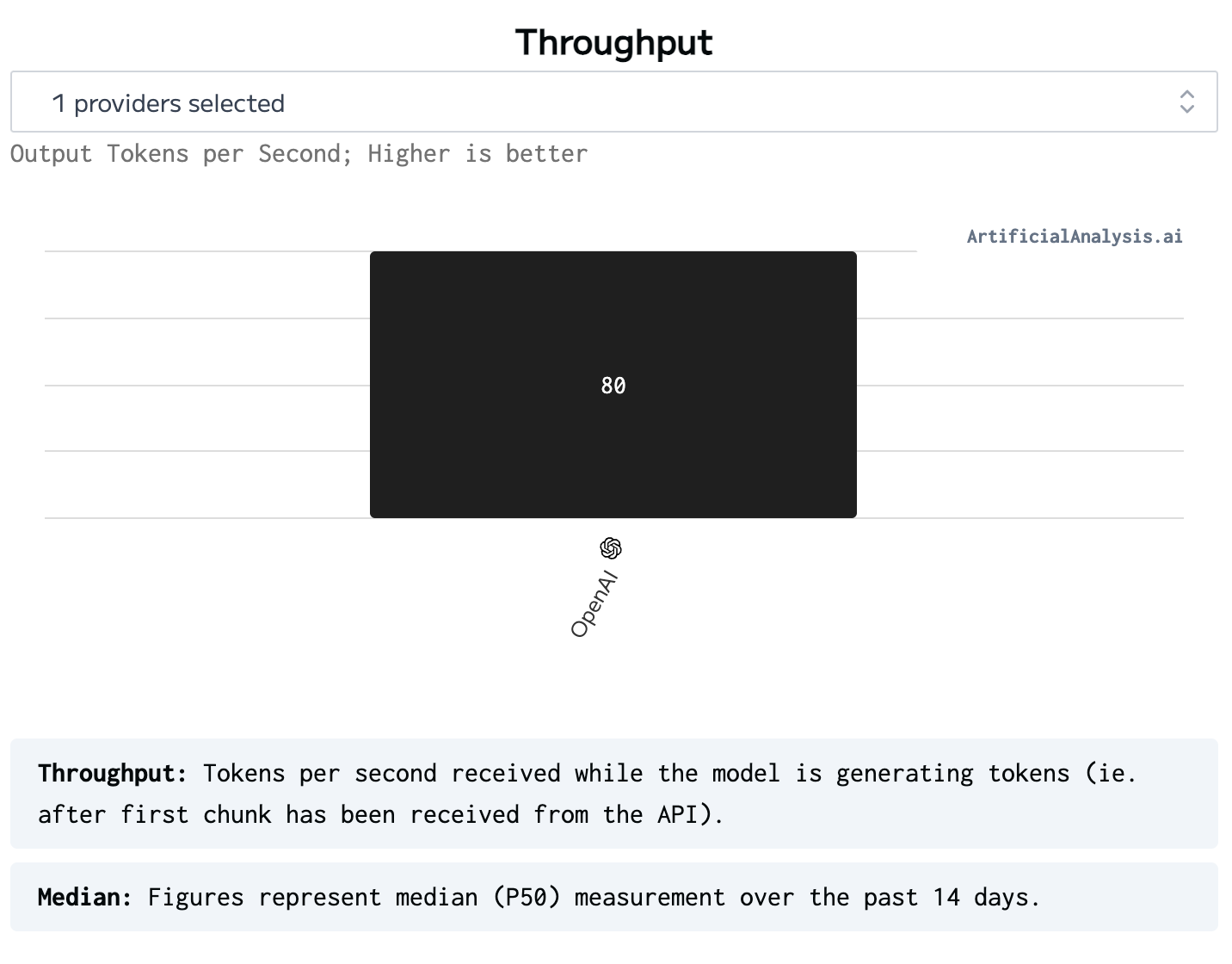 velocidade GPT4o
velocidade GPT4o
Conclusão
Para encerrar:
- AI não é LLM
- Você maomenos como uma LLM funciona
- A UI da OpenAI é AMAIS
- Se você não coda, chatGPT é brabo, mas procure outros provedores e modelos e se divirta
- Se você coda, voc6e devia definitivamente estar olhando para outros modelos e provedores dependendo do seu use-case
- Todos LLMs deveriam ser abertos :(
Valeu,
Gabs